%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Identity Preservation
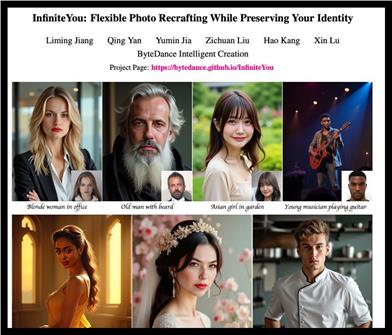
Infiniteyou
InfiniteYou (InfU) is a powerful diffusion-transformer-based framework designed for flexible image reconstruction while preserving user identity. By introducing identity features and employing a multi-stage training strategy, it significantly improves the quality and aesthetics of image generation while enhancing text-to-image alignment. This technology is important for improving the similarity and aesthetics of image generation and is suitable for various image generation tasks.
Image Generation
86.1K

Colorflow
ColorFlow is a model designed for coloring image sequences, with a particular focus on preserving the identity of characters and objects during the coloring process. Utilizing contextual information, it accurately generates colors for different elements (such as hair and clothing) in black-and-white image sequences based on a pool of reference images, ensuring consistency with the color references. Through a three-phase diffusion model framework, ColorFlow introduces a novel retrieval-augmented coloring workflow that achieves relevant image coloring without the need for fine-tuning each identity or extracting explicit identity embeddings. Its main advantages include high-quality coloring effects while retaining identity information, which is of significant market value for coloring cartoon or comic series.
Image Editing
55.8K
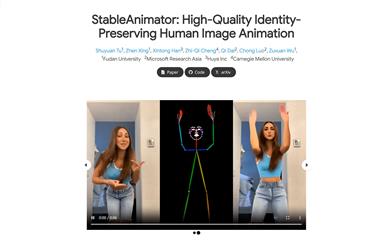
Stableanimator
StableAnimator is the first end-to-end identity-preserving video diffusion framework that synthesizes high-quality videos without the need for post-processing. This technology ensures identity consistency through conditional synthesis based on reference images and a series of poses. Its main advantage is that it does not rely on third-party tools, making it suitable for users who need high-quality portrait animations.
Video Production
72.6K

Diffusion Self Distillation
Diffusion Self-Distillation is a self-distillation technique based on diffusion models for zero-shot custom image generation. This technology allows artists and users to generate their own datasets via a pre-trained text-to-image model without requiring large paired datasets, enabling them to fine-tune the model for image-to-image tasks conditioned on text and images. This approach surpasses existing zero-shot methods in maintaining performance on identity generation tasks and can rival instance-based tuning techniques without the need for optimization during testing.
Image Generation
106.8K

Consisid
ConsisID is a frequency decomposition-based identity-preserving text-to-video generation model that generates high-fidelity videos consistent with the input textual descriptions using identity control signals in the frequency domain. This model does not require tedious fine-tuning for different cases and is capable of maintaining consistency in character identity within the generated videos. The introduction of ConsisID advances video generation technology, particularly in terms of streamlined processes and frequency-aware identity preservation control schemes.
Video Production
59.6K

Disenvisioner
DisEnvisioner is an advanced image generation technology that creates customized images by separating and enhancing thematic features, eliminating the need for tedious adjustments or reliance on multiple reference images. This technology effectively distinguishes and enhances thematic features while filtering out irrelevant attributes, achieving exceptional personalization in terms of editability and identity preservation. The research basis of DisEnvisioner stems from the current demand in the field of image generation for extracting thematic features from visual cues, tackling challenges faced by existing technologies through innovative approaches.
AI image generation
56.3K
Stableidentity
StableIdentity is a latest advancement based on large pre-trained text-to-image models, capable of achieving high-quality, human-centric generation. Unlike existing methods, StableIdentity ensures the stable retention of identity and flexible editability, even when training is conducted using only one facial image of each subject. It utilizes a facial encoder and identity prior to encode the input face, then projects the facial representation into an editable prior space. By combining identity priors and editability priors, the learned identity can be injected into various contexts. Additionally, StableIdentity incorporates a masked two-stage diffusion loss to enhance pixel-level perception of the input face and maintain the diversity of generation. Extensive experiments demonstrate that StableIdentity outperforms previous customization methods. The learned identity can also be flexibly combined with existing modules like ControlNet. Notably, we are the first to directly inject identities learned from a single image into video/3D generation without fine-tuning. We believe that StableIdentity is an important step towards unifying image, video, and 3D customization generation models.
AI image generation
68.4K
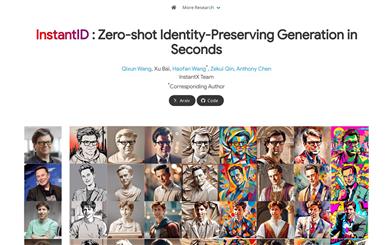
Instantid
InstantID is a solution based on powerful diffusion models that enables personalized image processing of a single face image across various styles while ensuring high fidelity. We designed a novel IdentityNet that, through the application of strong semantic and weak spatial constraints, integrates face and landmark images with textual prompts to guide image generation. InstantID performs remarkably well in practical applications and can seamlessly integrate with popular pre-trained text-to-image diffusion models (such as SD1.5 and SDXL) as an adaptable plugin. Our code and pre-trained checkpoints will be provided at [URL].
AI image generation
622.1K
Featured AI Tools
Chinese Picks

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
143.8K
Fresh Picks

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
109.8K
English Picks

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
125.3K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
98.0K
English Picks

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
63.5K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
88.9K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
660.5K
Chinese Picks

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M